Backing Up Tanzu Kubernetes Grid Integrated Edition
Backing up a Tanzu Kubernetes Grid Integrated Edition (TKGI, formerly known as PKS) installation is a bit of a mishmash of different elements. Unfortunately TKGI doesn’t support image based backups, neither does Kubernetes, before we look at the tools at your disposal what components require backing up?
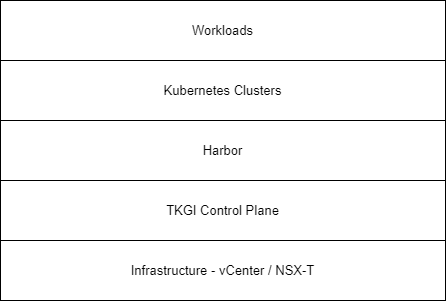
This diagram shows each layer of a TKGI deployment, let’s step through each layer and discuss the options for backing it up.
Infrastructure (vCenter / NSX-T)
Bread and butter backups here - point the appliance at the appropriate endpoint and hit go. I won’t go into much more detail as this is well documented.
TKGI Control Plane
First, what do we mean by the TKGI Control Plane? Specifically we mean these elements:
- TKGI Management Console (Optional)
- Ops Manager
- BOSH Director
- TKGI
TKGI Management Console
This is not backed up on a scheduled basis. At deployment time, and each time you make a change, you can export the configuration. The exported configuration does not include the identity management components, so these will need documenting so they can be added back in after a restore.
The configuration is exported in plain text, YAML format. There are a couple of passwords stored in here so it pays to be careful of where this file is stored.
In the event of a failure, you can deploy a fresh appliance and import the configuration. When importing the configuration the appliance will deploy a vanilla copy of of TKGI.
Ops Manager
This is also not backed up on a scheduled basis. The configuration can be exported, and you should after each change.
The configuration is exported and encrypted. It would be wise not to lose the encryption passphrase.
In the event of a failure, the Ops Manager OVA can be deployed and configuration imported. As opposed to the Management Console, you can select which items to process (deploy) after importing the configuration.
Generally speaking, you’d only export the configuration if you’re not managing the deployment with the Management Console.
BOSH Director
BOSH Backup & Restore (BBR) is the option here. BBR is a CLI tool that, when installed on a jumpbox, call a BBR script located on the BOSH Director. This BBR script will run a pre-backup freeze script, run the backups & then run a post-backup unfreeze script. The backup artifacts that it creates are copied back to the original jumpbox. Key point about the jumpbox - it needs to be located in an area of the network that has direct access to the backup targets.
Now BBR doesn’t have any retention smarts built in so that will need to be managed within a script of some description. The scheduling side of the equation will need to be managed by either cron or potentially as a pre-backup task within your backup software of choice.
These items are backed up from BOSH Director:
- Director Configuration
- CredHub Database
- UAA Database
- Blobstore
You’ll need the bbr private SSH key (found from the credentials tab in Ops Manager) to enable you to run the below command:
bbr director --hostname director IP --private-key-path /path/to/your/key backupoperation --artifact-path /path/to/store/backup/artifact
The backup operations that can be run are below. They’re all fairly self-explanatory except the cleanup operations, at least I think so.
| Backup operation | Description |
|---|---|
| pre-backup-check | Check Director is able to be backed up |
| backup | Run the backup |
| restore | restore the backup |
| backup-cleanup | Tidy up after a failed backup |
| restore-cleanup | Tidy up after a failed restore |
The comamnd to run is actually slightly different for a restore, but we’ll cover that in another post.
TKGI API / Database
BBR is the option here as well with a slight difference on the options defined with BBR. You’ll need:
- Target (BOSH_ENVIRONMENT variable)
- Username (BOSH_CLIENT variable)
- Password (BOSH_SECRET variable)
- CA Cert (Either CA_CERT or BOSH_CA_CERT variable)
When the deployments are backed up, you can either specify the pivotal-container-service deployment or specify all-deployments. This will cover all the Kubernetes deployments as well (to be covered shortly). This command assumes you’ve got the BOSH environment variables set.
bbr deployment --all-deployments backup --artifact-path /path/to/store/backup/artifact
Alternatively:
bbr deployement --deployment pivotal-container-service-deploymentuuid --artifact-path /path/to/store/backup/artifact
The artifact that is created will be stored in the specified location in the format: deployment-name_guid_datetime
Having the timestamp available in the directory structure makes life a little easier for managing the artifacts and also makes it more human readable when you need to restore.
Kubernetes Clusters
You’ve got two options here, either BBR or Velero. The option is actually both!
Using BBR will give you a point in time snapshot of etcd. This covers all workloads but no data. It’s primary use case is if you need to restore the entire cluster. While it is possible to restore individual workloads by restoring etcd to a different cluster, it’s pretty painful.
As a Kubernetes cluster is a BOSH deployment, BBR backs a cluster up in the same way.
Kubernetes Workloads
While a BBR backup of the cluster will cover all the stateless workloads, how do you backup the persistent disks? This is definitely where Velero can come in, as well as making it much simpler to restore (or migrate) individual workloads.
I’m not going to cover how to install & use Velero as that is already covered in plenty of detail on the interwebs. The highlights of the product (which I love) are:
- Backup to S3 compatible endpoint
- Backup by namespace
- Accessible to developers (quick on-demand backup prior to a change anyone?)
- Storage plugins based around CSI are becoming available
The key point from a TKGI perspective, is the cluster needs to have privileged containers enabled. As usual when privileged containers are allowed to run on your cluster, you should control this with some sort of Pod Security Policy.
Harbor
Harbor isn’t covered by BBR or Velero. How you approach the backup depends on what you selected for the storage option when you deployed Harbor. If you backup this location within your normal backup strategy then you’re gold. To backup the configuration, and the container registry if local, check out this KB.
Backup Artifacts
BBR is a decent tool, pretty clunky, but it works. What it doesn’t do is manage any of the backup artifacts. What I often see is a customer backing up the backup target (BBR jump box / S3 endpoint) with their existing backup product which takes care of any retention policies you want to adhere to. Then to manage the BBR backup artifacts themselves, run a cleanup script. This can be triggered either as a post backup task, or scheduled with cron. Velero is a bit smarter about managing the backup artifacts so that is less of a concern.
Summary
This is a quick overview of backing up a TKGI deployment. In my experience I’ve seen everything from all the backups run, to nothing and relying on Kubernetes manifests to recover from failure. Ultimately every business has their own choice to make based around their recovery strategy!